Preface
Recently, I finish reading the Game Engine Architecture [2]. There is a tech called Fiber-Based Job System, which impresses me and I was thinking it should be a good project to play with, because it is not so big and can be useful. So, I spent some days on implementing it and the first version of it just finishes today. Now, I think it maybe the time to write down something about it for reference in future. And, I think it can also be beneficial to others who are interested in implementing their own job system.
This is the Github repo of this project: Gardener Job System. Currently, it only supports Windows and I only tested it on MSVC. But, I’ll let it also work on the Ubuntu. If you need any help on configuring it, please let me know. You can find the Discord link in the repo’s readme. (Or, you can submit an issue.)
On the internet, there are also other people who did this Fiber-based job system before [6] [7] [8] [9]. But it looks like they have been deprecated for a while. As for [9], it looks like the author put it into his game engine and maintains it there. So, that is not 100% deprecated.
Introduction
The first time that I came across this concept is when I was reading the Game Engine Architecture 8.6.4.5 section. In its parent section 8.6.4, the author also introduces other techniques that can be used as the base of a job system, such as threads or coroutines. Then, why did the Naughty Dog choose fibers as their base of the job system? According to the materials [2] [3], I think they even though talked about some characteristics and advantages of the fiber, but they didn’t clearly state its advantages over the coroutine. So, the following statements about the advantages of fiber over coroutine contain personally thoughts, which maybe incorrect.
First, let’s compare threads and fibers. Fibers’ context switch is much faster than threads’ context switch, because fibers’ context switch doesn’t involve operations from the kernel. According to [5],
A context switch between threads usually costs thousands of CPU cycles on x86, compared to a fiber switch with less than a hundred cycles.
In a job system, context switch is common, because each jobs is small and most of them use asynchronous resources. So, the performance advantage is attractive.
Besides, by comparing coroutines and fibers, their performance don’t have a big difference. But, from the perspective of implementation, fibers are more convenient than coroutines. In a job system, we need a scheduler to decide which job to run next when the current job finishes or is blocked. For fibers, normally you can find a default scheduler (like the round-robin one if you use the boost library), while coroutines don’t have a default scheduler.
For the readability, I’ll simply introduce coroutines, fibers and threads in my mind to explain why fibers have the advantages mentioned above. However, in order to fully understand these concepts, I recommend you refer [1]’s section 8.1, 8.2, 12.3, and [4], [5].
Process, thread, coroutine, fiber and boost::fibers
A process is an instance of a program in execution. Its context includes the program’s code, data in its memory, stack, general purpose registers, program counter, environment variables and open files’ descriptors. I think there are two important traits for a process: 1. A process provides an independent logical control flow and 2. It provides a private address space.
A thread is a logical flow running in the context of a process. It is automatically scheduled by the kernel. Each threads has their own context. The context of a thread includes its unique thread ID, stack, stack pointer, program counter, general purpose registers and its state code. All threads in a process share the virtual address space of the process. This virtual address space includes a process’ code, data stack, shared library and open files’ descriptor.
A coroutine is similar to a function. When a thread executes a coroutine, the control is given to the coroutine. When the coroutine yields, the control would be given back to the caller thread. The difference between a coroutine and a function is that a coroutine can resume at the place where it yields, while a function can only restart after it ends.
A fiber is similar to a thread, so it is often called a user-space thread. It is same as a thread, which has its own context. The context of a fiber includes stack, program counter, general purpose registers. The difference between a thread and a fiber is that a fiber runs in a thread and belongs to this thread. At one time, a thread can only run one fiber. Meanwhile, other fibers on this thread need to wait for this fiber. Besides, the context switch of a fiber should also be explicit. Users need to write code in the fiber to specify when a fiber should yield and which fiber should come next. Because of this, the collaboration between fibers is cooperative instead of preemptive. And, the context switch of the fiber doesn’t involve kernel.
So, a fiber is better than a thread in performance and better than a coroutine in flexibility.
According to [2] and [3], it looks like they were implementing fiber by themselves (Or, maybe there is one in their FreeBSD-Based OS?). But now, we can use Boost anyway and that is cross-OS. Here, I am going to simply introduce the important things to know and caveats, from my perspective. For more details, please refer [5] and its subsequent chapters.
- Before deleting a fiber, you should call
.join()or the fiber would report an error when it tries to call the.terminate(), even though you are confident that the fiber has finished its job. - The
boost::fibers::mutex‘s.lock()is a spin-lock. So, if you cannot get the mutex, you will spend CPU cycles waiting for the mutex instead of giving out the control. So, in some scenarios, we should usewhile(!try_lock()){ yield() }to replace.lock(). - It is not convenient to configure/build the boost library from its source code. And I think it is almost impossible to use boost as a submodule of a git repo. So, I think a viable way to include boost into your project is to tell users to download the boost installer by themselves and you can use CMake’s Find_Package(…) to find the installed boost folder by asking the user for a path.
Fiber-based Job System
Then, let’s take a look at how Naughty Dog defines a Job System in [2] [3].

We can see that it majorly includes these parts: Job Queue, Worker Thread, Fiber Pool, Wait List. At first, the system would initialize a Fiber Pool. Then, users can put jobs into the Job Queue and a Worker Thread would grab a job from the queue if it sees one and uses that job to create a fiber. If the job needs to wait for any resources, then the system would put the fiber into a wait list and increase the counter of the Wait List. If the fiber gets the resource, then it would decrease one for the counter. Then, if the Worker Thread has free cycles, it would check the Wait List first. If it sees that the counter is 0, then the thread resumes the waiting fiber. After the job finishes, the Worker Thread returns the fiber back to the fiber pool.
Besides, each Worker Threads is attached to a core. Even though there is no jobs in the job queue, the Worker Thread still runs in an infinite loop instead of yielding the CPU core.
As a job system, it should have the following feature [2] (Section 8.6.4.1):
- Spawn a job or a set of jobs.
- Allow a job to wait for a job or a set of jobs.
- Allow a job to terminate earily.
- Provide concurrent operation with spin-lock.
- Allow a job to be paused and resumed.
- A priority mechanism.
My Fiber-based Job System Version 1
As its first version, I only select some of the functionalities. Besides, due to the fact that boost::fibers has already implemented some of the mentioned functionalities (e.g. spin-lock mutex), we can save lots of time. So, my job system has following functionalities:
- Spawn a job.
- Allow the main thread to wait for all jobs finish.
- Provide spin-lock for concurrent operations. (Already in boost::fibers)
- Allow a job to be paused and resumed. (Already in boost::fibers)
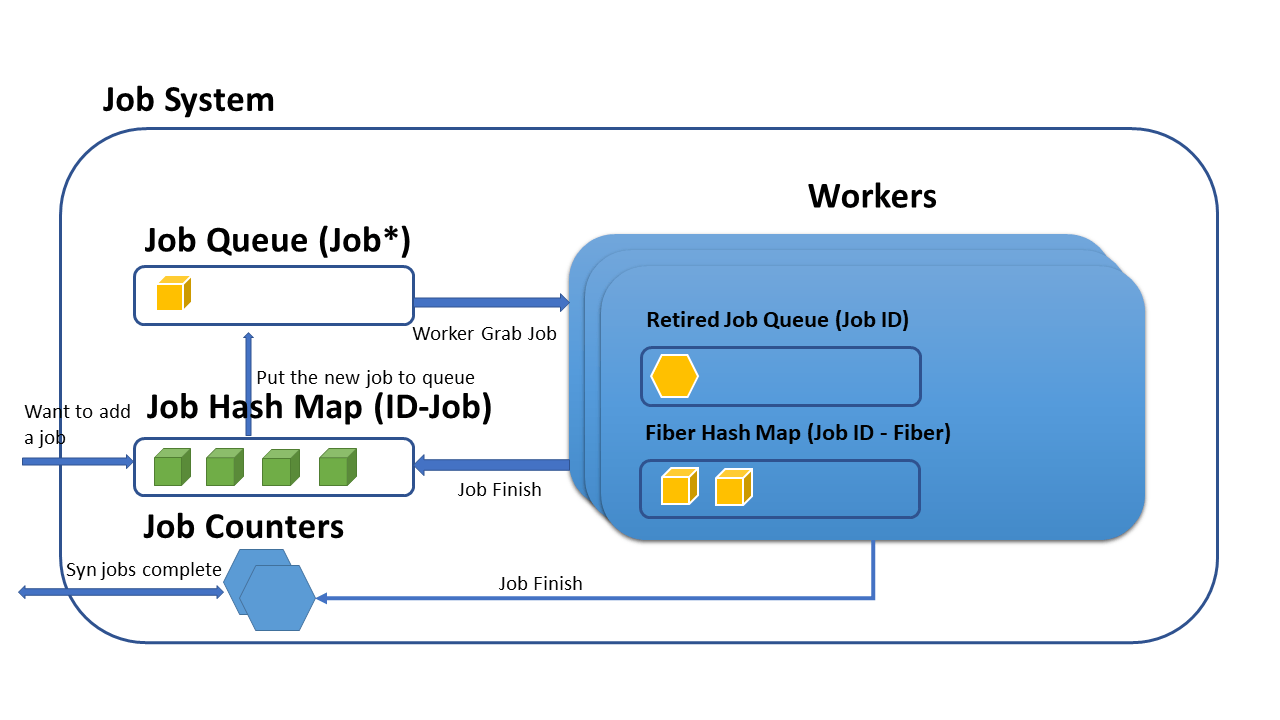
Overall, the whole system looks like this:
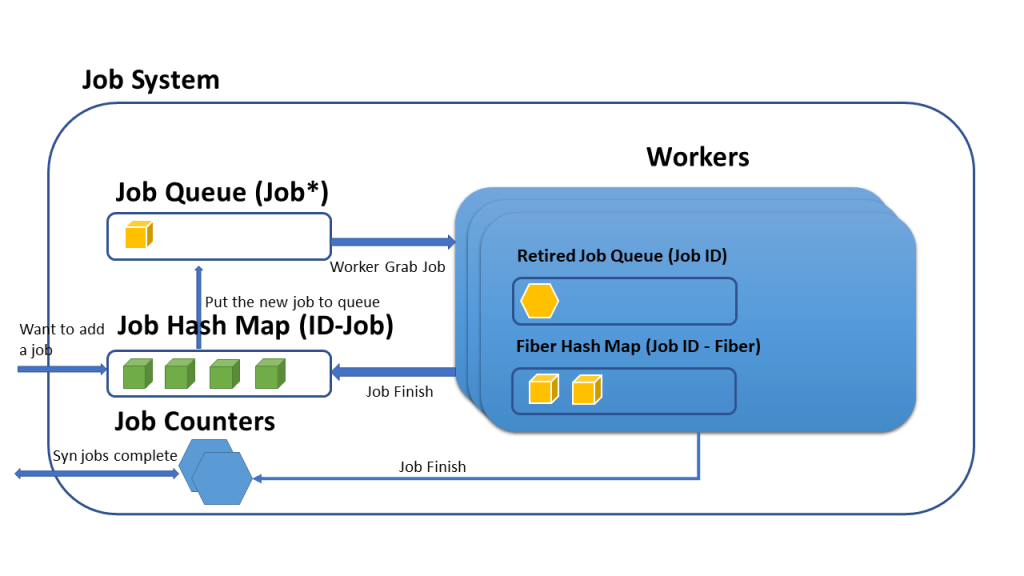
First, the user needs to initialize this job system. During initialization, the user needs to specify how many threads needed, which should be less than the number of CPU cores that the user has, because this system will use this info to specify threads’ core affinity. Then the user needs to pass a task function pointer to the job system through its interface. The signature looks like this: void MyTaskClass::MyTaskFoo(MyTaskClass* pTaskClass). Then, a job is basically equivalent to the function passed in. Besides, when the user calls the interface to add a job, the system adds one to the Served Job Counter, which will be used for synchronization.
After the job system gets the function pointer, the function pointer will be used to create a job and the job will be given an unique ID. The ID-Job pair is stored into a hash map managed by the job system. Subsequently, the job pointer is put into the job queue in the job system and workers will individually get the job pointer from this job queue to create a fiber. The jobID-Fiber pair is stored in each workers’ hash map.
When a fiber finishes, the job id of the fiber is put into the retired queue in the worker. Each workers’ main fiber (Boost thinks the thread used to spawns fibers is a main fiber) would check the retied job queue constantly. If there is an ID in it, the main fiber would inform the job system and add one to the Finished Job Counter in the job system.
By using the Served Job Counter and the Finished Job Counter mentioned above, we can implement the synchronization logic in the main thread. E.g. If these two counters have same values, then we know that all submitted jobs have already finished.
Interface
The interface of the system looks like this:
class CustomTask
{
static void MyTaskFunc(CustomTask* pThisTask){...}
uint64_t m_taskId;
}
void main()
{
...
Gardener::JobSystem jobSys(runThreadNum);
CustomTask task;
jobSys.AddAJob(&task->MyTaskFunc, &task, tasks.m_taskId);
...
jobSys.WaitJobsComplete();
...
}Through AddAJob(...) we can give the system a function pointer of the task that we want to use. Besides, we also need to feed in an address of the task instance and the address of its ID variable so the system can fill the ID.
By using the WaitJobsComplete() we can wait until all submitted jobs done in the main thread.
Let’s take a look at a more illustrative example.
Example
class CustomTask
{
public:
CustomTask(uint32_t taskId)
: m_taskId(taskId)
{}
~CustomTask() {}
static void MyTaskFunc(CustomTask* pThisTask)
{
pThisTask->m_taskRes = pThisTask->m_taskId * pThisTask->m_taskId;
}
void PrintTaskRes()
{
std::cout << "Task #" << m_taskId << ": "
<< m_taskRes << std::endl;
}
uint64_t m_taskId;
private:
uint32_t m_taskRes;
};
int main()
{
CustomTask* tasks[10];
for (uint32_t i = 0; i < 10; i++)
{
tasks[i] = new CustomTask(i);
}
uint32_t runThreadNum = std::thread::hardware_concurrency() / 2;
Gardener::JobSystem jobSys(runThreadNum);
for (uint32_t i = 0; i < 10; i++)
{
jobSys.AddAJob(&tasks[i]->MyTaskFunc, tasks[i], tasks[i]->m_taskId);
}
jobSys.WaitJobsComplete();
for (uint32_t i = 0; i < 10; i++)
{
tasks[i]->PrintTaskRes();
delete tasks[i];
}
}The task here is just calculating the square of the ID of the task instance and print that out. It needs to first send tasks. Then waiting for it. Finally, the example prints out the results.
Building and using this project
A user can use the following building command under the example or test folder:
cmake -B build -G "Visual Studio 16 2019" -DBOOST_ROOT=C:\boost_1_81_0One thing needed notes is that BOOST_ROOT needs to be your boost install path.
If you have any problems or advices, please let me know. You can find me at this Discord server: https://discord.gg/ZmXaZUJzvF.
Plans and future
Possible application
I think it maybe served as the underlining tech behind most graphics application as long as the app can be CPU bound. So, no matter whether that is a renderer or a game engine, we can make use of it as long as we can divide works into small jobs.
My plan is to use it as a submodule of my game engine and explore its use cases.
More works on the project
In the future, I think I should add an interface to submit a set of jobs. Besides, it should also work on Ubuntu and I need to test it under that.
References
- Computer Systems A Programmer’s Perspective, Third Edition
- Game Engine Architecture, Third Edition
- Parallelizing the Naughty Dog engine using fibers
- Boost Fiber Proposal
- Boost Fiber Overview
- https://pjako.github.io/fiber-based-job-system/
- https://github.com/krzysztofmarecki/JobSystem
- https://github.com/nem0/lucy_job_system
- https://github.com/pjako/task_system
